Those who have read my papers (assumed there are) may have noticed I seem to obssessed with the small multiple plots, as they appeared in almost all my papers. I get accquited with the small multiple plots through Edward Tufte’s book.
About the data
| E | G | phaseAngleB | logEta | temp | fc | Va | Vbeff | p200 | p4 | p38 | p34 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3.968853 | -0.0107657 | -0.2011322 | 0.4072264 | -0.7797781 | -0.6969864 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 4.074047 | 0.4364826 | -0.5388009 | 0.4072264 | -0.7797781 | -0.3453411 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 4.156582 | 1.2328548 | -0.8014321 | 0.4072264 | -0.7797781 | 1.0612403 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 3.434015 | -0.6947925 | 0.7368364 | -0.3908505 | -0.0133754 | -0.6969864 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 3.624560 | -0.6622266 | 0.3757185 | -0.3908505 | -0.0133754 | -0.3453411 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 3.789856 | -0.5831582 | 0.0521194 | -0.3908505 | -0.0133754 | 1.0612403 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 2.781519 | -0.7079397 | 1.2245801 | -0.9991320 | 0.7530274 | -0.6969864 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 3.014610 | -0.7064110 | 0.8962911 | -0.9991320 | 0.7530274 | -0.3453411 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 3.243353 | -0.7007653 | 0.5773818 | -0.9991320 | 0.7530274 | 1.0612403 | -1.115502 | 0.5253402 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
| 3.962371 | -0.0107657 | -0.2011322 | 0.4072264 | -0.7797781 | -0.6969864 | -1.579263 | 0.5790654 | 0.5381223 | -1.273332 | -0.1213407 | 1.343846 |
The data used here contains 12 variables (11 features and one target (\(|E^*|\), e-star) and a total 7400 samples. This is not a small data set for the perspective of scatter matrix. As many small plots are to be included in the matrix, the actual data to be presented are hundreds times of the entire data set. Hence, the plot matrix contains millions of data points. As a side, the \(|E^*|\) of asphalt concrete is a critical parameter both for asphalt pavement design and asphalt mixture characterization.
Also, for acedemic papers, I always prefer vectorized figures rather than ones in bitmap. However, the plotting and rending of pdf figures with a large number of data are painfully slow. To reduce my pain a bit, I have attempted many recipes without much success. To get the ball rolling, here I provide my own not-so-successful attempts to motivate greater mind’s perfect solution.
Show the results of different tools
Use pairs of the R base graphics
The following figures showed the I made with the pairs function from the R base graphics. The matrix plots comprise three parts: scatter plots along with a loess-smoothed curve, histograms show the distribution of the variables, and the correlation coefficients for each pair of variables. The labels sit on top of the histograms are the corresponding variable names. The “nice-looking” labels are typesetted using LaTeX, which often causes more pain due to its desparating slowness.

scatterMatrix <- function(data = data, pch=16, cex=0.75,
cex.cor2=3, labels=lab_in_math, family="serif") {
xfun::pkg_attach2(c("rlm"))
myCol <- c( "#440152FF", "#FDE725FF", "#29AF7FFF", "#33638DFF" )
## correlation panel: scale corr coefs in propotion to their values
panel.cor <- function(x, y, digits = 2, prefix = "", cex.cor=cex.cor, ...){
usr <- par("usr"); on.exit(usr)
par(usr = c(0, 1, 0, 1))
## correlation coefficient
r <- abs(cor(x, y, use = "complete.obs"))
txt <- format(c(r, 0.123456789), digits = digits)[1]
txt <- paste0(prefix, txt)
if (missing(cex.cor)) {
cex.cor <- 0.9/strwidth(txt)
}
text(0.5, 0.5, txt, cex = cex.cor * (1 + r) * cex.cor2/2)
box(lwd=0.1)
}
# hexbin panel
# panel.hex <- function(x, y, ...) {
# panel.hexbinplot(x, y, type=c("s"), ...)
# panel.loess(x, y, col = adjustcolor('orange3'), lwd=2, ... )
# }
## histogram panel
panel.hist <- function(x, ...) {
usr <- par("usr")
on.exit(usr)
par(usr = c(usr[1:2], 0, 1.5))
h <- hist(x, plot = FALSE)
breaks <- h$breaks
nB <- length(breaks)
y <- h$counts
y <- y/max(y)
rect(breaks[-nB], 0, breaks[-1], y, col = myCol[3], border="white",... )
box(lwd=0.1)
}
## point plots with loess-smoothed curves
panel.smooth2 <- function(x, y, pointCol=myCol[4], lineCol=myCol[2], ...) {
panel.smooth(x, y,
col=adjustcolor(pointCol, alpha.f=1/5),
col.smooth = adjustcolor("orange3", alpha.f=0.6),
cex=0.2, pch=pch, bg="white", lwd=2)
box(lwd=0.1)
}
## scatter plot with smooth
# panel.lm <- function(x, y,
# pointCol = adjustcolor("#525252", alpha.f = 0.3),
# lineCol = adjustcolor(myCol[1], alpha.f=0.5),
# bg="white", pch=shape, ...) {
# points(x, y, pch = pch, cex = 0.3, col = pointCol, bg = bg)
# abline(stats::lm(x~y, na.omit=TRUE), col = lineCol, lwd = 3, ...)
# box(lwd=0.2)
# }
par(mgp=c(3, 0.1, 0), family=family)
p <- pairs(~.,
cex.axis = 1.1,
cex.labels = 1.15,
font.labels = 2,
cex = cex,
tck=0.01,
data = data,
labels=labels,
lower.panel=panel.smooth2,
diag.panel=panel.hist,
upper.panel=panel.cor,
bty="n",
gap=0/3,
oma=c(2,2,3,2)
)
print(p)
}Just plug in the data and call the scatterMatrix() function.
Use the lattice package
I made the second product using the splom in the lattice package, which has been a strong competitor of the ggplot2. The splom reads as scatter plot matrix.
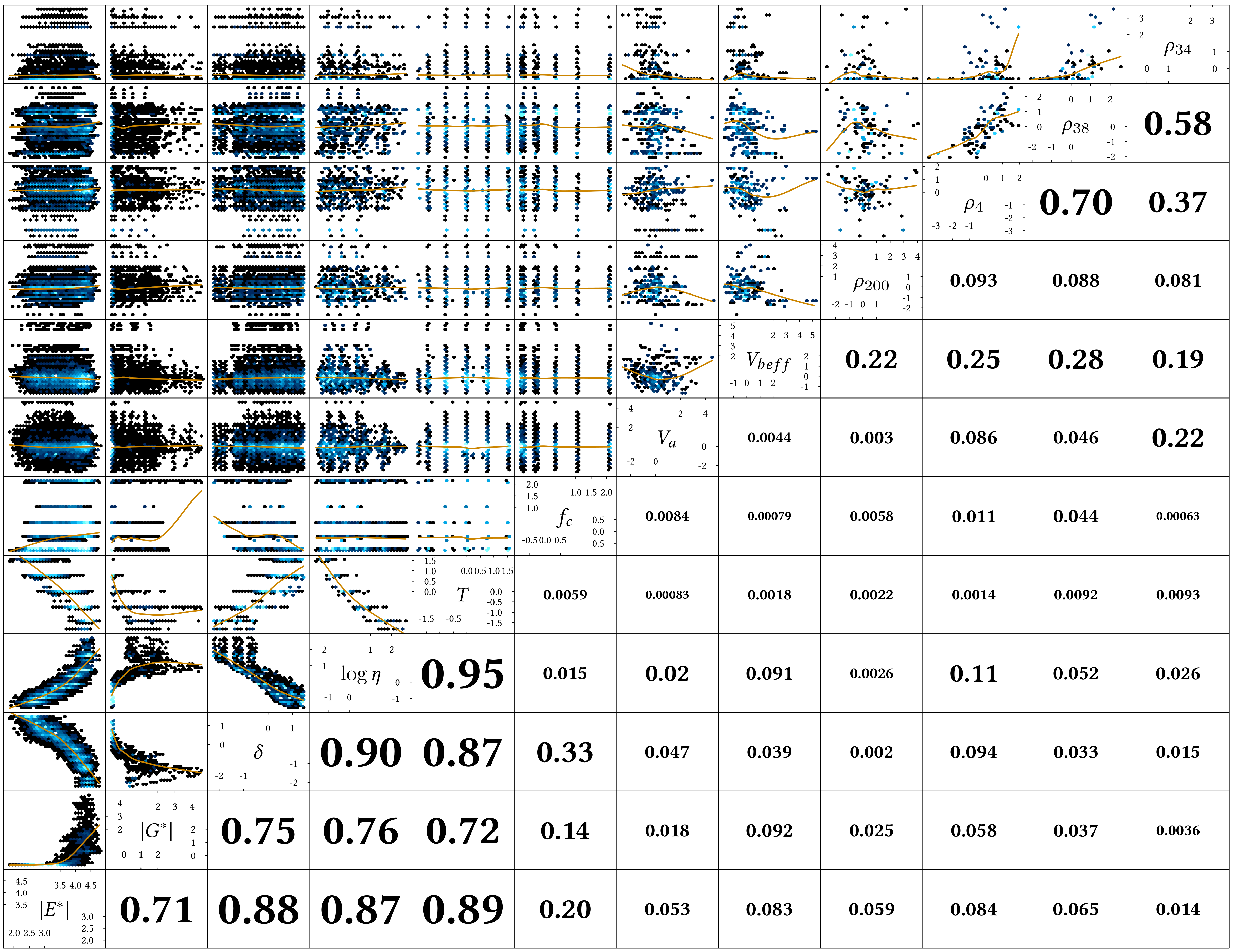
The following R code snippet shows how it is made:
library(lattice)
# library(tikzDevice) # typeset the plot in latex through the tikz library
# when plotting a large data set, the tikz is extremely slow and causes a huge load of computation
# texpath <- "scatter-matrix.tex"
# fw <- 8
# asp_ratio <- 1.2
# fh <- fw/asp_ratio
# tikz(file=texpath, standAlone=TRUE, width=fw, height=fh)
splom(~d,
upper.panel = panel.hexbinplot, # hexbin plot used instead of point plot for speed
xbins=50, # a small number of bins used for speed
lower.panel = function(x, y, ...) {
r <- abs(cor(x, y, use = "complete.obs"))
digits <- 2
txt <- format(c(r, 0.123456789), digits = digits)[1]
txt <- paste0("", txt)
corrSize <- 0.5/strwidth(txt)
corrSize <- corrSize * (1 + r) / 20 # scale the size of corr in proportion to its value
panel.text(sum(range(x))/2,
sum(range(y))/2,
txt,
font = 2,
cex=corrSize
)
},
raster=TRUE,
aspect=1/1.4,
varnames=labels_tex # typeset variable using latex
)
# dev.off()The actual code needed is quite concise and relatively fast (3 min for 2.8GHz macbook pro) if rendered in png or pdf. When using the tikz, it can take up to 10 minutes.
Use matplotlib from Python

I am actually most satisfied with the one made with matplotlib, which is the fastest. The drawback is that you need a little bit boilerplate coding. As you see in the following snippet, it is the most straightforward (stupid?^_^) solution.
import pandas as pd
import numpy as np
import matplotlib as mpl
from matplotlib import font_manager as fm
from matplotlib import rc
## setup font for latex
mpl.rcParamsDefault
mpl.rcParams['text.usetex'] = True
mpl.rcParams['text.latex.preamble'] = [r'\usepackage[T1]{fontenc}',
r'\usepackage{libertine}',
r'\usepackage[libertine]{newtxmath}'
]
# load data
data = pd.read_csv('input/data.csv')
nvars = data.shape[1] # fetch the total number of the variables
var_names = ['$|E^*|$', '$|G^*|$', '$\delta_b$', '$\log\eta$',
'$T$', '$f_c$', '$V_a$', '$V_{\mathrm{beff}}$',
'$p_{200}$', '$p_4$', '$p_{38}$', '$p_{34}$'] # name of variables in latex
# used to adjust the positions of the variables names
label_x = [0.25, 0.5, 0.5, 0.75, 0.42, 0.5,
0.75, 0.65,0.75, 0.3, 0.8, 0.5]
# the actual function does the heavy and dirty job
def scatterMatrix(i, j):
if i > j:
ax[i, j].plot(data.iloc[:, i], data.iloc[:, j],
'o', markersize=1/4, color='#cc6677', alpha=1/3)
if j == 0:
ax[i, j].xaxis.set_major_locator(plt.NullLocator())
ax[i, j].xaxis.set_major_formatter(plt.NullFormatter())
elif i == (nvars-1):
ax[i, j].yaxis.set_major_locator(plt.NullLocator())
ax[i, j].yaxis.set_major_formatter(plt.NullFormatter())
else:
ax[i, j].xaxis.set_major_locator(plt.NullLocator())
ax[i, j].xaxis.set_major_formatter(plt.NullFormatter())
ax[i, j].yaxis.set_major_locator(plt.NullLocator())
ax[i, j].yaxis.set_major_formatter(plt.NullFormatter())
if i==1 and j==0:
ax[i, j].text(x=0.5, y=0.2, ha='center', va='center',
transform=ax[i, j].transAxes,
s='$|G^*|$ vs. $|E^*|$', fontsize=6, color='#000000')
elif i < j:
corr = np.abs(np.corrcoef(data.iloc[:, i], data.iloc[:, j])[0,1])
ax[i, j].text(x=0.5, y=0.5,
ha='center', va='center',
s=f"{corr:.3f}",
transform=ax[i, j].transAxes,
fontsize=(corr+1)*10, weight='bold')
ax[i, j].yaxis.set_major_locator(plt.NullLocator())
ax[i, j].yaxis.set_major_formatter(plt.NullFormatter())
ax[i, j].xaxis.set_major_locator(plt.NullLocator())
ax[i, j].xaxis.set_major_formatter(plt.NullFormatter())
else:
ax[i,j].hist(data.iloc[:, i], bins=6,
edgecolor='white', color='#999933')
ax[i, j].text(x=label_x[i], y=0.75, ha='center', va='center',
transform=ax[i, j].transAxes,
s=var_names[i], fontsize=12, color='#000000')
ax[i, j].yaxis.set_major_locator(plt.NullLocator())
ax[i, j].yaxis.set_major_formatter(plt.NullFormatter())
ax[i, j].xaxis.set_major_locator(plt.NullLocator())
ax[i, j].xaxis.set_major_formatter(plt.NullFormatter())
fw = 8
fig, ax = plt.subplots(nvars, nvars, sharex=False, sharey=False, figsize=(fw, fw/1.25))
for i in range(nvars):
for j in range(nvars):
scatterMatrix(i, j)
fig.tight_layout(pad=0, h_pad=0, w_pad=0)
fig.subplots_adjust(hspace = 0, wspace=0)
fig_type = 'pdf'
if fig_type == 'pdf':
figpath = '../texsrc/figures/sm-py.pdf'
else:
figpath = '../texsrc/figures/sm-py.png'
if fig_type == 'pdf':
plt.savefig(figpath)
else:
plt.savefig(figpath, dpi=600)Use ggplot2
Originally, I attempted to come up with a solution similar to the one in matplotlib, but failed to use the regular loop as did in the matplotlib. It may be possible to use some functional, such as using lapply or the map_ functions from the purrr package.

library(GGally) # install.package("GGally")
d %>%
# sample_n(200) %>% # used a small subset for illustration
rename(
`eta[b]` = phaseAngleB,
`log~eta` = logEta,
`T` = temp,
`f[c]` = fc,
`V[a]` = Va,
`V[beff]` = Vbeff,
`p[200]`=p200,
`p[4]`=p4,
`p[38]`=p38,
`p[34]`=p34
) %>%
ggpairs(
upper=list(continuous=wrap(ggally_cor, color='#000000', size=3)),
lower=list(continuous=wrap(ggally_points, shape=19, size=1/3,
alpha=1/4, color='navy')),
diag=list(continuous=wrap(ggally_densityDiag, size=1/2, n=8,
color='grey51', fill='grey60')),
labeller = "label_parsed"
) +
theme_clean(base_size = 10) +
theme(panel.grid.major=element_blank(),
panel.grid.minor=element_blank(),
axis.text.x=element_text(angle=90)
)